

V tomto článku se podíváme na konfiguraci konfigurace převzetí služeb při selhání ze dvou proxy serverů pro squid, aby uživatelé mohli přistupovat k Internetu z podnikové sítě s jednoduchým vyrovnáváním zatížení pomocí služby Round Robin DNS. Chcete-li vytvořit konfiguraci převzetí služeb při selhání, vytvoříme pomocí clusteru HA udržovaný.
HA cluster - Jedná se o skupinu serverů s vestavěnou redundancí, která je vytvořena za účelem minimalizace prostojů aplikace v případě problémů s hardwarem nebo softwarem jednoho z členů skupiny. Na základě této definice je pro provoz HA klastru nutné implementovat následující:
- Kontrola stavu serverů;
- Automatické přepínání zdrojů v případě selhání serveru;
Oba tyto úkoly umožňují zachování. Keepalived - systémový démon v systémech Linux, který umožňuje organizovat odolnost proti chybám služby a vyrovnávání zatížení. Odolnost proti poruchám je dosaženo díky „plovoucí“ adrese IP, která se přepne na záložní server v případě selhání hlavní. Protokol se používá k automatickému přepínání IP adres mezi udržovanými servery VRRP (Virtual Router Redundancy Protocol), je standardizovaný, popsaný v RFC (https://www.ietf.org/rfc/rfc2338.txt).
Obsah:
- Principy VRRP
- Nainstalujte a nakonfigurujte udržované na CentOS
- Keepalived: monitorujte stav aplikací a rozhraní
- Keepalived: testování převzetí služeb při selhání
Principy VRRP
Nejprve musíte zvážit teorii a základní definice protokolu VRRP.
- VIP - Virtual IP, virtuální IP adresa, která se v případě selhání může automaticky přepínat mezi servery;
- Master - server, na kterém je VIP aktuálně aktivní;
- Zálohování - servery, na které se VIP přepne v případě selhání průvodce;
- VRID - Virtual Router ID, servery spojené společnou virtuální IP (VIP), tvoří tzv. Virtuální router, jehož jedinečný identifikátor nabývá hodnot od 1 do 255. Server se může současně skládat z několika VRID s jedinečnými virtuálními IP adresami pro každý VRID.
Obecný algoritmus práce:
- Hlavní server odešle pakety VRRP na vyhrazenou adresu vícesměrového vysílání (vícesměrové vysílání) 224.0.0.18 s určeným intervalem a všechny podřízené servery tuto adresu poslouchají. Multicast mailing je, když odesílatel je jeden, a tam může být mnoho příjemců.
Je důležité. Aby servery fungovaly v režimu vícesměrového vysílání, musí síťové zařízení podporovat přenos vícesměrového přenosu. - Pokud server Slave nepřijímá pakety, spustí postup výběru Master a pokud se prioritně přepne do stavu Master, aktivuje VIP a jedy bezdůvodný ARP. Gratuitous ARP je speciální druh odpovědi ARP, která aktualizuje tabulku MAC na připojených přepínačích, aby vás informovala o změně vlastnictví virtuální adresy IP a adresy MAC pro přesměrování provozu.
Nainstalujte a nakonfigurujte udržované na CentOS
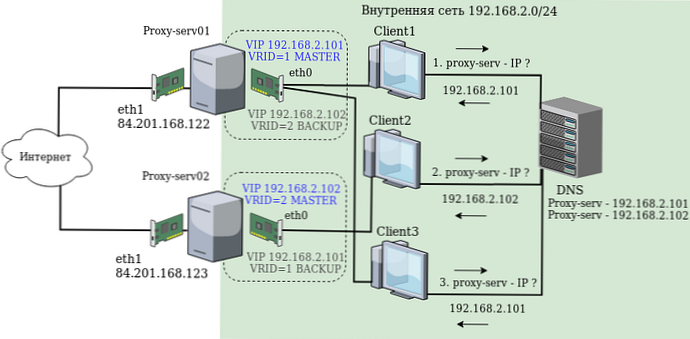
Instalace a konfigurace bude provedena na příkladu servery proxy-serv01 a proxy-serv02 na Centos 7 s nainstalovaným Squid. V našem schématu použijeme nejjednodušší metodu vyrovnávání zatížení (vyvažování) - Round Robin DNS. Tato metoda předpokládá, že pro jedno jméno je v DNS zaregistrováno několik adres DNS a klienti na požádání obdrží jednu adresu najednou, pak druhou. Proto budeme potřebovat dvě virtuální adresy IP, které budou zaregistrovány v DNS se stejným názvem a které klienti nakonec kontaktují. Schéma sítě:
Každý server Linux má dvě fyzická síťová rozhraní: eth1 s bílou IP adresou a přístupem na internet a eth0 v místní síti.
Jako skutečné adresy IP serveru se používají:
192.168.2.251 - pro proxy-server01
192.168.2.252 - pro proxy-server02
Jako virtuální adresy IP se používají následující, které se v případě selhání automaticky přepínají mezi servery:
192.168.2.101
192.168.2.102
Nainstalujte balíček keepalived na oba servery pomocí příkazu:
yum instalace keepalived
Po dokončení instalace na obou serverech upravte konfigurační soubor
/etc/keepalived/keepalived.conf
Barevné zvýrazněné čáry s různými parametry:
| na serveru proxy-serv01 | na serveru proxy-serv02 |
 | 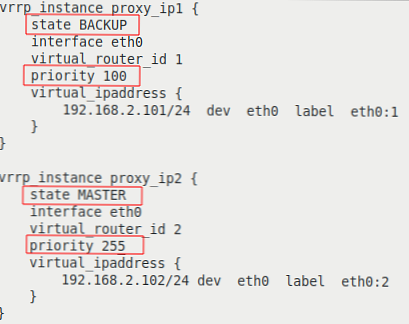 |
Budeme analyzovat možnosti podrobněji:
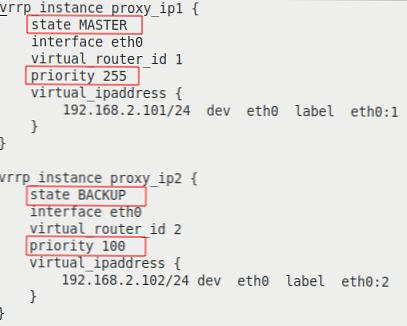
- vrrp_instance - Část definující instanci VRRP;
- stav - počáteční stav při spuštění;
- interface - rozhraní, na kterém bude VRRP spuštěn;
- virtual_router_id - jedinečný identifikátor instance VRRP se musí shodovat na všech serverech;
- priorita - nastaví prioritu při výběru MASTER, server s nejvyšší prioritou se stane MASTER;
- virtual_ipaddress - blok virtuálních IP adres, které budou aktivní na serveru ve stavu MASTER. Musí se shodovat na všech serverech v instanci VRRP.
Pokud současná konfigurace sítě neumožňuje vícesměrové vysílání, má Keepalived možnost použít jednosměrové vysílání, tj. odesílat pakety VRRP přímo na servery uvedené v seznamu. Chcete-li použít unicast, budete potřebovat možnosti:
- unicast_src_ip - zdrojová adresa pro pakety VRRP;
- unicast_peer - blok IP adres serverů, na které budou zasílány pakety VRPP.
Naše konfigurace tedy definuje dvě instance VRRP, proxy_ip1 a proxy_ip2. Během normálního provozu bude server proxy-serv01 MASTER pro virtuální IP 192.168.2.101 a BACKUP pro 192.168.2.102 a server proxy-serv02 bude MASTER pro virtuální IP 192.168.2.102 a BACKUP pro 192.168.2.101.
Je-li na serveru aktivován firewall, musíte přidat permisivní pravidla pro vícesměrový přenos a protokol vrrp pomocí iptables:
iptables -A INPUT -i eth0 -d 224.0.0.0/8 -j ACCEPT
iptables -A INPUT -p vrrp -i eth0 -j ACCEPT
Aktivujeme spouštění a spouštíme udržovanou službu na obou serverech:
systemctl povolit keepalived
systemctl start keepalived
Po spuštění udržované služby budou rozhraním z konfiguračního souboru přiřazeny virtuální adresy IP. Podívejme se na aktuální adresy IP na rozhraní serveru eth0:
ip show eth0
Na serveru proxy-serv01:

Na serveru proxy-serv02:

Keepalived: monitorujte stav aplikací a rozhraní
Díky protokolu VRRP je možné sledovat stav serveru, například během úplné fyzické poruchy serveru nebo síťového portu na serveru nebo přepínači. Jsou však možné i jiné problematické situace:
- chyba ve službě proxy serveru - klienti, kteří se dostanou na virtuální adresu tohoto serveru, obdrží v prohlížeči zprávu s chybou, že proxy server není k dispozici;
- odmítnutí druhého internetového rozhraní - klienti, kteří se dostanou na virtuální adresu tohoto serveru, obdrží v prohlížeči zprávu s chybou, že připojení nelze navázat.
K řešení výše uvedených situací použijeme následující možnosti:
- track_interface - monitorování stavu rozhraní; stav VRRP se uvede do stavu FAULT, pokud je jedno z uvedených rozhraní ve stavu DOWN;
- track_script - monitorování pomocí skriptu, který by měl vrátit 0, pokud ověření proběhlo úspěšně, 1 - pokud ověření selhalo.
Aktualizujte konfiguraci, přidejte monitorování rozhraní eth1 (ve výchozím nastavení bude instance VRRP kontrolovat rozhraní, ke kterému je vázána, tj. V aktuální konfiguraci eth0):
track_interface eth1
Směrnice track_script spustí skript s parametry definovanými v bloku vrrp_script, který má následující formát:
vrrp_script interval skriptu - frekvence skriptu, výchozí 1 sekunda pádu - kolikrát skript vrátil nenulovou hodnotu, při které se přepne do stavu FAULT state - kolikrát skript vrátil nulovou hodnotu, při které opustí stav FAULT timeout - timeout, dokud skript nevrátí výsledek, po kterém vrátí nenulovou hodnotu. weight - hodnota, o kterou bude priorita serveru snížena v případě přechodu do stavu FAULT. Výchozí hodnota je 0, což znamená, že server se po neúspěšném spuštění skriptu přepne do stavu FAULT, kolikrát je určen parametrem fall.
Konfigurace sledování chobotnice. Můžete ověřit, že proces je aktivní pomocí příkazu:
squid -k check
Vytvořit vrrp_script, s parametry frekvence provádění každé 3 sekundy. Tento blok je definován mimo bloky. vrrp_instance.
vrrp_script chk_squid_service script "/ usr / sbin / squid -k check" interval 3
Přidejte náš skript k monitorování uvnitř obou bloků vrrp_instance:
track_script chk_squid_service
Pokud se nyní Squid proxy služba nezdaří, virtuální IP adresa se přepne na jiný server.
Můžete přidat další akce když se změní stav serveru.
Pokud je Squid nakonfigurován tak, aby přijímal připojení z jakéhokoli rozhraní, tj. http_port 0.0.0.0 128, pak při přepínání virtuální IP adresy nebudou problémy, Squid přijme připojení na novou adresu. Pokud jsou však nakonfigurovány konkrétní adresy IP, například:
http_port 192.168.2.101 128 http_port 192.168.2.102 možná128
pak Squid nebude vědět, že se v systému objevila nová adresa, kde musíte poslouchat požadavky klientů. K řešení takových situací, kdy je třeba při přepínání virtuální adresy IP provést další akce, obsahuje Keepalived možnost provést skript, když nastane událost, když se změní stav serveru, například z MASTER na BACKUP nebo naopak. Je implementována možností:
oznámit "cesta ke spustitelnému souboru"
Keepalived: testování převzetí služeb při selhání
Po nastavení virtuální adresy IP zkontrolujeme, jak správně dochází ke zpracování selhání. Prvním testem je simulace selhání jednoho ze serverů. Odpojíme od sítě interní síťové rozhraní eth0 serveru proxy-serv01, zatímco zastaví odesílání paketů VRRP a server proxy-serv02 musí aktivovat virtuální adresu IP 192.168.2.101. Výsledek zkontrolujeme příkazem:
ip show eth0
Na serveru proxy-serv01:

Na serveru proxy-serv02:
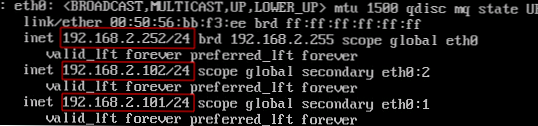
Podle očekávání server proxy-serv02 aktivoval virtuální adresu IP 192.168.2.101. Uvidíme, co se stalo v protokolech s příkazem:
cat / var / log / messages | grep -i udržovaný
| na serveru proxy-serv01 | na serveru proxy-serv02 |
Keepalived_vrrp [xxxxx]: Jádro hlásí: interface eth0 DOWN Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) Zadání FAULT STATE Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) odebírá VIP VIP protokol. Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) Nyní ve stavu FAULT | Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) Přechod na MASTER STATE |
| Keepalived přijímá signál, že rozhraní eth0 je ve stavu DOWN, a uvádí instanci VRRP proxy_ip1 do stavu FAULT a uvolňuje virtuální adresy IP.. | Keepalived uvede instanci VRRP proxy_ip1 do stavu MASTER, aktivuje adresu 192.168.2.101 na eth0 a pošle bezdůvodný ARP. |


A zkontrolujeme, že po připojení rozhraní eth0 na serveru proxy-serv01 k síti se virtuální IP 192.168.2.101 přepne zpět.
| na serveru proxy-serv01 | na serveru proxy-serv02 |
Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) vynutit nové volby MASTER Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) Přechod na MASTER STATE Keepalived_vrrp [Keepback] VIP Keepalived_vrrp [xxxxx]: Odesílání bezdůvodného ARP na eth0 za 192.168.2.101 | Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) Přijatý inzerát s vyšší prioritou 255, našich 100 Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) Zadání ZÁLOŽNÍ STÁT Keepalived_vrrp [xxxxx]: VRRP__string). |
| Keepalived přijímá signál k obnovení rozhraní eth0 a začíná nové volby MASTER pro instanci VRRP proxy_ip1. Po přechodu do stavu MASTER aktivuje na rozhraní eth0 adresu 192.168.2.101 a odešle bezdůvodný ARP. | Keepalived obdrží paket vysoké priority pro instanci VRRP proxy_ip1 a uvede proxy_ip1 do stavu BACKUP a uvolní virtuální IP adresy. |
Druhým testem je simulace selhání externího síťového rozhraní, proto odpojíme externí síťové rozhraní eth1 proxy-serv01 serveru od sítě. Výsledek kontroly zkontrolujeme pomocí protokolů.
| na serveru proxy-serv01 | na serveru proxy-serv02 |
Keepalived_vrrp [xxxxx]: Jádro hlásí: interface eth1 DOWN Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) Zadání FAULT STATE Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) odebírá VIP VIP protokol. Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) Nyní ve stavu FAULT | Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) Přechod na MASTER STATE Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) Zadání MASTER STATE Keepalived_vrrp [xxxxx]: VRRP_Insts. Proxy. Protocol Keepalived_vrrp [xxxxx]: Odesílání bezdůvodného ARP na eth0 za 192.168.2.101 |
| Keepalived přijímá signál, že rozhraní eth1 je ve stavu DOWN, a stav VRRP instance proxy_ip1 ve stavu FAULT uvolní virtuální IP adresy.. | Keepalived uvede instanci VRRP proxy_ip1 do stavu MASTER, aktivuje adresu 192.168.2.101 na eth0 a pošle bezdůvodný ARP. |

Třetí kontrola je napodobením selhání Squid proxy služby, proto tuto službu opustíme ručně příkazem: systemctl stop squid Výsledek kontroly zkontrolujeme pomocí protokolů.
| na serveru proxy-serv01 | na serveru proxy-serv02 |
Keepalived_vrrp [xxxxx]: VRRP_Script (chk_squid_service) selhal Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) Zadání FAULT STATE Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1). Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) Nyní ve stavu FAULT | Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) Přechod na MASTER STATE Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) Zadání MASTER STATE Keepalived_vrrp [xxxxx]: VRRP_Insts. Proxy. Protocol Keepalived_vrrp [xxxxx]: Odesílání bezdůvodného ARP na eth0 za 192.168.2.101 |
| Skript pro kontrolu aktivity chobotnice proxy selhal. Keepalived uvádí instanci VRRP proxy_ip1 do stavu FAULT a uvolňuje virtuální adresy IP. | Keepalived uvede instanci VRRP proxy_ip1 do stavu MASTER, aktivuje adresu 192.168.2.101 na eth0 a pošle bezdůvodný ARP. |
Všechny tři kontroly prošly úspěšně, správně nakonfigurované. V pokračování tohoto článku nakonfigurujeme HA klastr pomocí Pacemakeru a vezmeme v úvahu specifika každého z těchto nástrojů..
Konečný konfigurační soubor /etc/keepalived/keepalived.conf pro server proxy-serv01:
vrrp_script chk_squid_service script "/ usr / sbin / squid -k check" interval 3 vrrp_instance proxy_ip1 state MASTER interface eth0 virtual_router_id 1 priority 255 virtual_ipaddress 192.168.2.101/24 dev eth0 label eth0: 1 track_interface eth1 track_interface eth1 vrrp_instance proxy_ip2 state BACKUP interface eth0 virtual_router_id 2 priority 100 virtual_ipaddress 192.168.2.102/24 dev eth0 label eth0: 2 track_interface eth1 track_script chk_squid_service
Konečný konfigurační soubor /etc/keepalived/keepalived.conf pro server proxy-serv02:
vrrp_script chk_squid_service script "/ usr / sbin / squid -k check" interval 3 vrrp_instance proxy_ip1 state BACKUP interface eth0 virtual_router_id 1 priority 100 virtual_ipaddress 192.168.2.101/24 dev eth0 label eth0: 1 track_interface eth1 track_inter interface eth_inter_inter interface vrrp_instance proxy_ip2 state MASTER interface eth0 virtual_router_id 2 priority 255 virtual_ipaddress 192.168.2.102/24 dev eth0 label eth0: 2 track_interface eth1 track_script chk_squid_service


{kind=link}