

Jeden ze základních kamenů technologie identifikace a zabezpečení - Dynamické řízení přístupu (dynamická kontrola přístupu) v systému Windows Server 2012 je funkční Infrastruktura klasifikace souborů (FCI - Infrastruktury klasifikace souborů). FCI se používá na souborových serverech organizace a poskytuje možnost vytvářet nové vlastnosti a atributy(Vlastnosti klasifikace souborů) pro klasifikace souborů. FCI vám umožňuje automaticky klasifikovat soubory podle obsahu souboru nebo adresáře, ve kterém jsou umístěny; spravovat soubory (například období, během kterého je možný přístup k souboru); generovat zprávy ukazující distribuci klasifikačních vlastností na souborovém serveru. Soubory založené na klíčových slovech nebo vzorech lze automaticky klasifikovat například jako důvěrné nebo obsahující osobní údaje. Uživatel (vlastník) bez použití FCI však může soubory také klasifikovat ručně.
FCI je prvek Dynamic Access Control, který klasifikuje soubory přiřazením značek, na kterých závisí použití zásad DAC..
Poprvé technologie Infrastruktura klasifikace souborů Představeno v systému Windows Server 2008 R2. Jaké příležitosti poskytla? Pomocí FCI je možné implementovat různé scénáře zpracování dokumentů do úložišť souborů (včetně těch, které obsahují důvěrné informace): sběr, šifrování, přenos, archivace, odesílání po trase a mazání souborů. Pomocí FCI můžete například implementovat skript, který vám umožní automaticky přenášet soubory z drahého úložiště na levnější a pomalejší na základě klasifikace souborů, nebo například automaticky učinit soubory nepřístupnými po určité době.
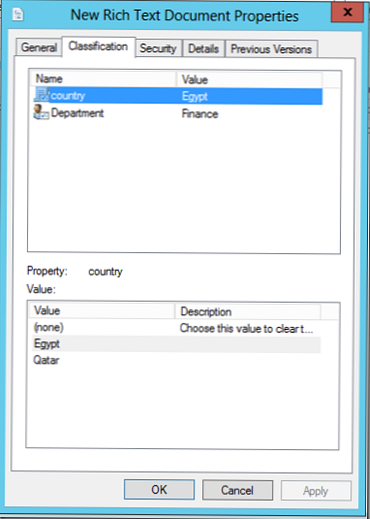
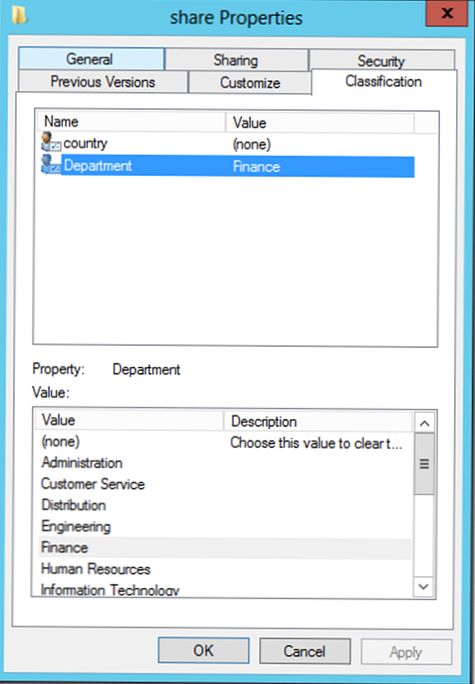
Snímek obrazovky níže ukazuje příklad souboru klasifikovaného jako součást egyptské země a oddělení „Finance“. Atributy klasifikace mohou být naprosto cokoli: například priorita, soukromí, umístění, organizace atd..
Jak ručně klasifikovat soubor nebo adresář
Soubory a adresáře lze třídit ručně otevřením okna vlastností objektu a výběrem možnosti „KlasifikaceV našem příkladu můžete z rozevíracího seznamu předdefinovaných hodnot vybrat jiné hodnoty pro atributy země a oddělení..
Automatická klasifikace
Chcete-li nakonfigurovat automatickou klasifikaci objektů v systému Windows Server 2012, musíte k instalaci role použít konzolu Server Manager Souborový server (souborový server).
Instalací komponenty Správce prostředků souborového serveru (FSRM), otevřete příslušnou konzolu MMC a mezi známými skupinami Kvóta, File Screening, File Management uvidíte novou podsekci Řízení klasifikace (management klasifikace), který se zase skládá ze dvou částí:
- Vlastnosti klasifikace - slouží k vytvoření atributů klasifikace (v našem příkladu jsou to atributy země a oddělení, které mají globální status, protože jsou publikovány v AD)
- Klasifikační pravidla - pravidla automatické klasifikace

Chcete-li nastavit automatickou klasifikaci dokumentů, musíte vytvořit pravidlo klasifikace.
Jedním ze způsobů, jak uspořádat automatickou klasifikaci souborů na základě umístění, je vlastnost klasifikace - SložkaPoužití. Toto je předdefinovaná vlastnost uložená v sekci Vlastnosti klasifikace. Ve výchozím nastavení definuje 4 typy dat:
- Aplikační data - aplikační data
- Zálohy - zálohovací data
- Data skupiny - data skupiny
- Uživatelské soubory - Uživatelské soubory
Zde si můžete vytvořit své vlastní datové typy..
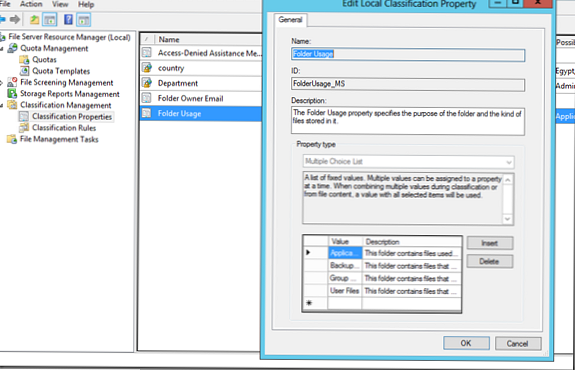
Zde vytvoříme vlastní typy složek pro finanční (finanční) a inženýrské oddělení (inženýrství) a poté musíme určit, které soubory patří k tomu oddělení (datový typ). Chcete-li to provést, klikněte na prázdné místo v konzole FSRM pod KlasifikaceVlastnosti a vyberte SetSložkaŘízeníVlastnosti
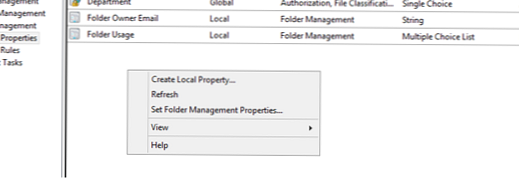
Vyberte vlastnost SložkaPoužití a určete složky, které budou používány jednotlivými odděleními nebo obsahují konkrétní datový typ. Je však třeba si uvědomit, že v tomto případě není nakonfigurována klasifikace souborů (nakonfigurujeme ji později), určíme vlastnictví složek, které použijeme v klasifikačním pravidle
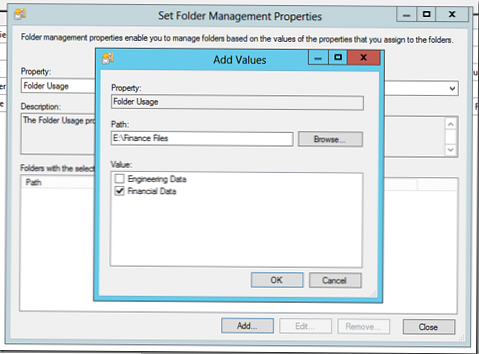
Nastavili jsme to takto:
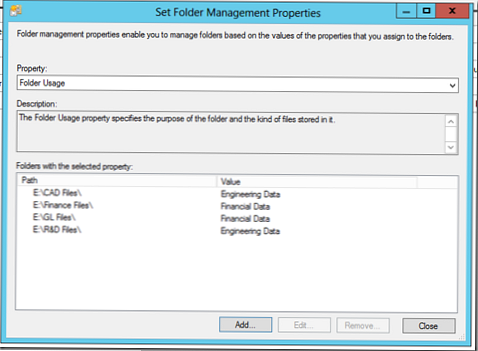
Vytvořte pravidlo klasifikace dat
Nastal čas v sekci KlasifikacePravidla vytvořit nové pravidlo (kontextová nabídka Vytvořit klasifikační pravidlo):
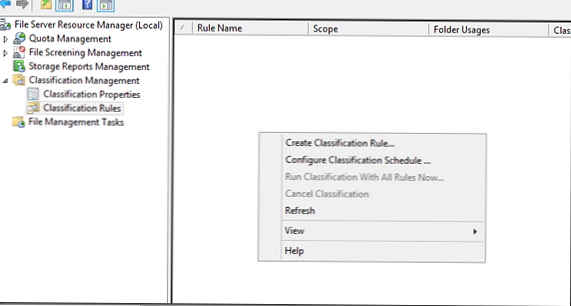
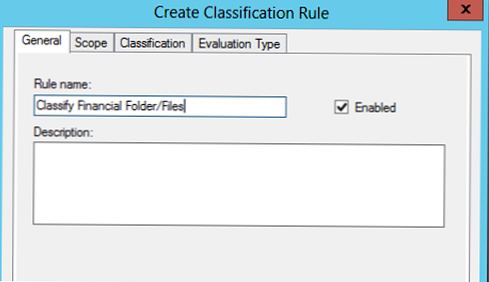
Uveďte název pravidla (vytváříme pravidlo pro klasifikaci souborů jako patřící finančnímu oddělení).
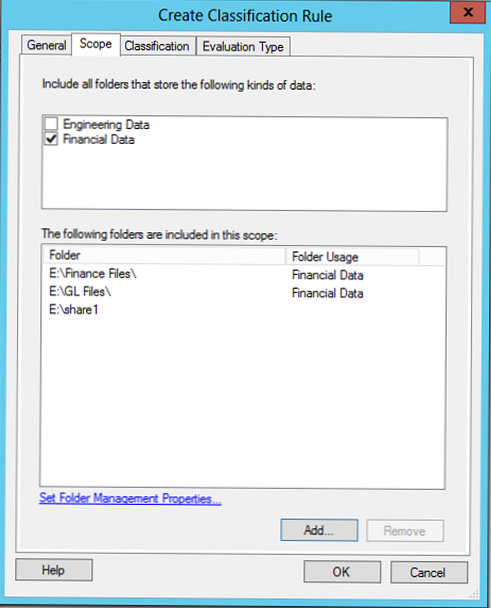
Tab Oblast působnosti označíme adresáře, které je třeba vzít v úvahu při provádění klasifikace, zvolíme pravidlo vytvořené dříve FinančníData (automaticky přidá všechny dříve vybrané složky), můžete také přidat adresáře ručně (v příkladu je to E: \ share1).
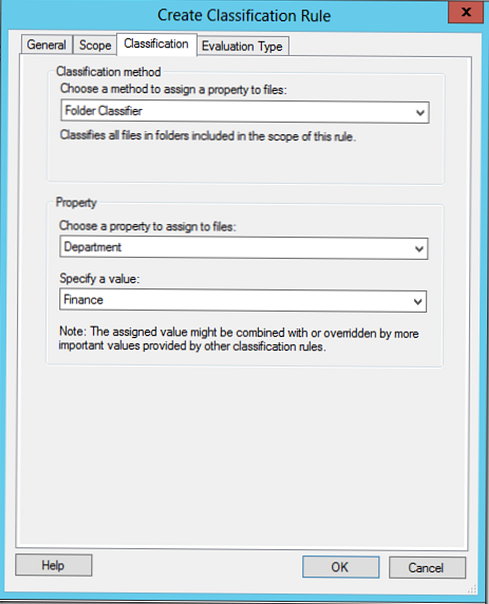
Tab Klasifikace Můžete si vybrat jednu ze dvou klasifikačních metod:
- Klasifikace složek - klasifikace založená na adresářích (atributy se vztahují na všechny soubory adresářů)
- Klasifikace obsahu - klasifikace podle obsahu souboru. V tomto případě jsou všechny soubory v adresáři prohledávány podle klíčových slov, vzorů nebo regulárních výrazů (čísla projektu, kreditní karty, identifikátory oddělení atd.).
Snímek obrazovky ukazuje klasifikační pravidlo založené na adresářích, klasifikační pravidlo podle obsahu bude popsáno níže.
Tab Typ hodnotící hodnoty Je uveden postup pro použití a opětovné použití klasifikačních pravidel na soubory. V níže uvedeném příkladu jsme uvedli, že systém může přepsat aktuální klasifikaci, čímž zaručujeme, že klasifikace uživatele bude přepsána firemním pravidlem.

V následujícím klasifikačním pravidle vytvoříme klasifikační pravidlo založené na obsahu souboru:
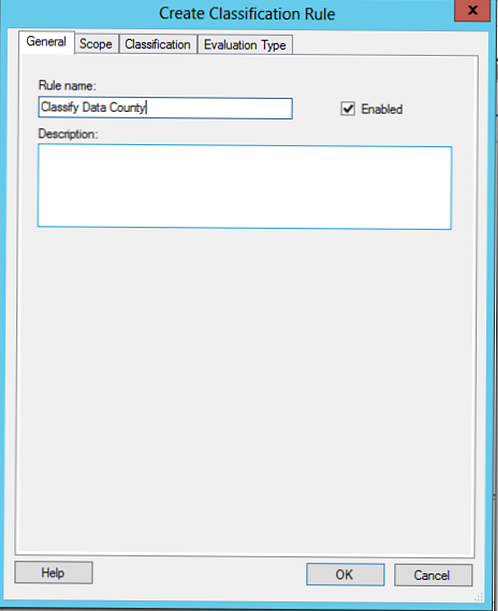
Toto pravidlo klasifikuje data podle zemí, takže k nim přidáme katalogy inženýrského i finančního oddělení.
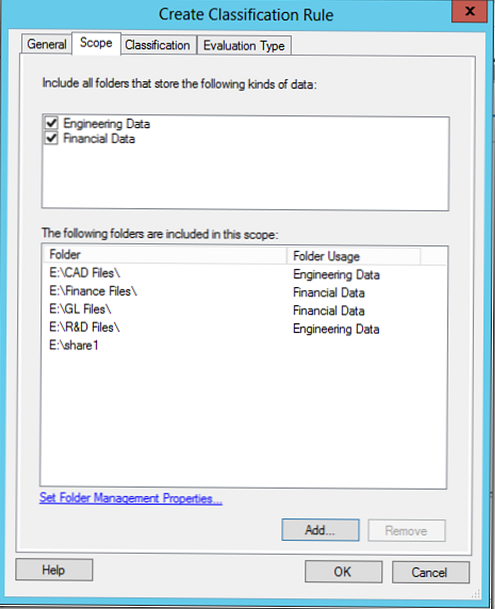
V tomto klasifikačním pravidle se na základě obsahu souboru pokusíme klasifikovat údaje týkající se Egyptské země.
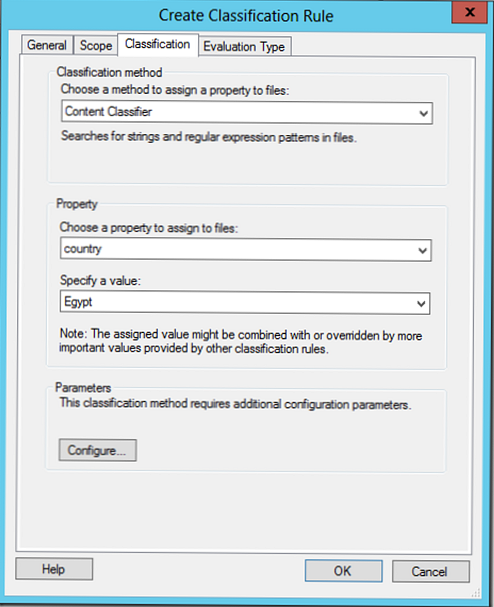
V části Parametry vyberte Konfigurovat. V zobrazeném okně můžete vyhledávat na základě regulárních výrazů, řetězců nebo řetězců citlivých na velikost písmen..
Pomocí regulárních výrazů můžete vyhledávat v textových dokumentech (včetně souboru TIFF) podle různých kritérií, například:
- Přítomnost kořenů ve slově, nevenování pozornosti případům a příponám
- Přítomnost slov nebo frází v náhodném pořadí
- Dostupnost dat ve specifickém formátu, jako jsou čísla kreditních karet, telefonní čísla, pasové údaje nebo e-mailové adresy
- Splnění podmínek pro určité množství schůzek požadovaných dat v souboru (například alespoň 3 kreditní karty nebo telefonní čísla)
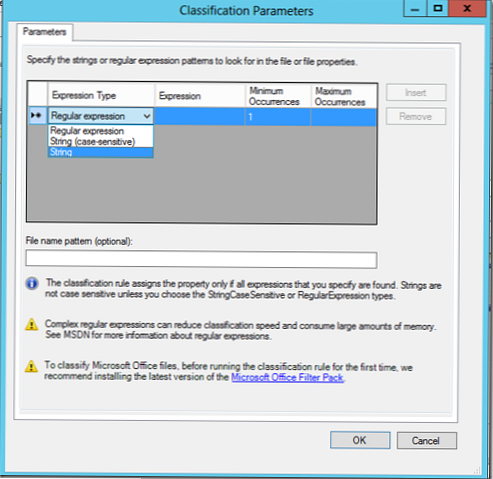
V našem příkladu budeme hledat dokumenty pomocí klíčového slova Egypt, a pokud bude nalezen, soubor by měl být klasifikován podle tohoto pravidla (můžete určit minimální a maximální počet výskytů klíčového slova v dokumentu).
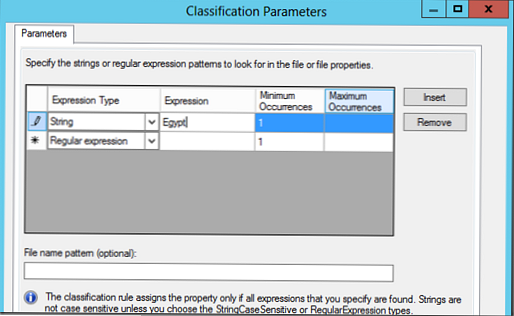
Vytvořili jsme tedy dvě klasifikační pravidla:
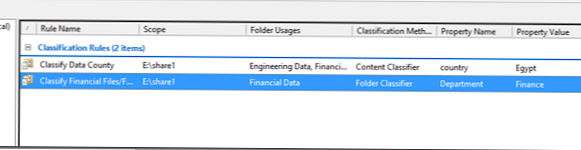
Nyní se pokusíme spustit automatickou klasifikaci souborů. Předpokládejme, že máme 2 soubory, z nichž jeden obsahuje slovo Egypt a druhý ne. Tyto soubory jsou umístěny v adresářích „Finanční soubory“ a „Soubory výzkumu a vývoje“, jak můžete vidět v okamžiku, kdy nejsou nijak klasifikovány..
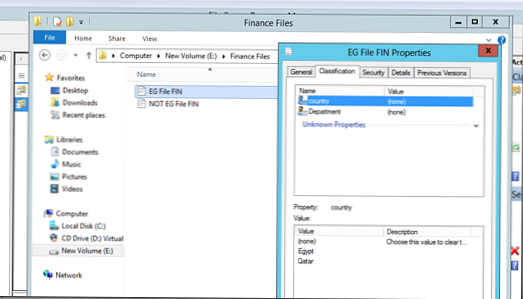
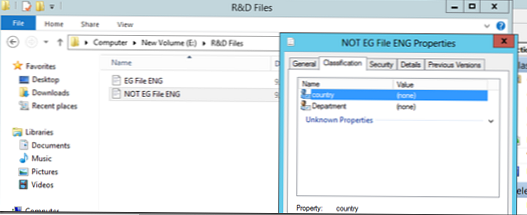
Spusťte naše klasifikační pravidla (Spusťte klasifikaci se všemi pravidly):
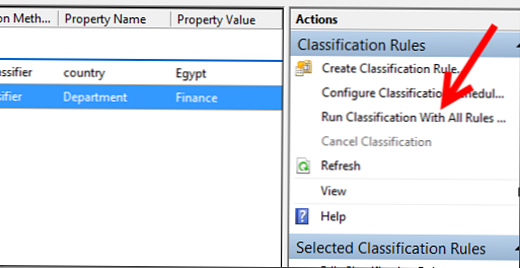
Výsledky pravidel lze nalézt ve zprávách ve zprávách..

Jak vidíte, vše fungovalo správně, ke souborům s klíčovým slovem byla přiřazena správná země a atribut Finance k celému obsahu katalogu finančního oddělení.
V této fázi nebyly provedeny žádné operace s utajovanými soubory, byly jednoduše označeny atributy, které jsme potřebovali. V budoucnu můžete na základě klasifikace souborů s nimi provádět různé operace, zejména šifrovat soubory pomocí služby AD RMS (příklad použití je popsán v článku Šifrování souborů pomocí služby AD RMS na základě infrastruktury klasifikace souborů Windows Server 2012) nebo řídit přístup k nim prostřednictvím systému Windows Server 2012 Dynamic Access Control. Tyto aspekty budeme zvažovat v dalších článcích v sérii..

{kind=link}